
GCG
Branch-and-Price & Column Generation for Everyone
Branch-and-Price & Column Generation for Everyone
This use-case is still in development and may be incomplete. Please excuse any inconveniences.
In this use case, we develop a branch-and-price algorithm for a combinatorial optimization problem without writing a single line of code. We only need to be able formulate our problem as a (mixed) integer program. For that we will use the ZIMPL modeling language.
We consider a variant of a classic NP-hard combinatorial optimization problem. Given an undirected graph \(G=(V,E)\), a dominating set \(S\subseteq V\) is a subset of the vertices, such that every vertex \(i \in V\) is in \(S\) or adjacent to a vertex in \(S\). We say that every vertex not in \(S\) is dominated by a vertex in \(S\). For the capacitated dominating set problem we are additionally given vertex weights \(u:V\rightarrow \mathbb{Z}_+\). Loosely speaking, every vertex \(i \in V\) can dominate at most \(u(i)\) many other vertices. More formally, a subset \(S\subseteq V\) is a capacitated dominating set if and only if there exists a mapping \(f:V\setminus S\rightarrow S\) such that the number of vertices mapped under \(f\) to \(i\in S\) is no more than \(u(i)\).
The following example graph is taken from [5]. All vertices have capacity 2, and a minimum capacitated dominated set consists of e.g., \(S=\{2,6,7,8,12\}\). An arc \((i,j)\) is interpreted as '' \(i\) is dominated by \(j\),'' representing a possible mapping \(f\).
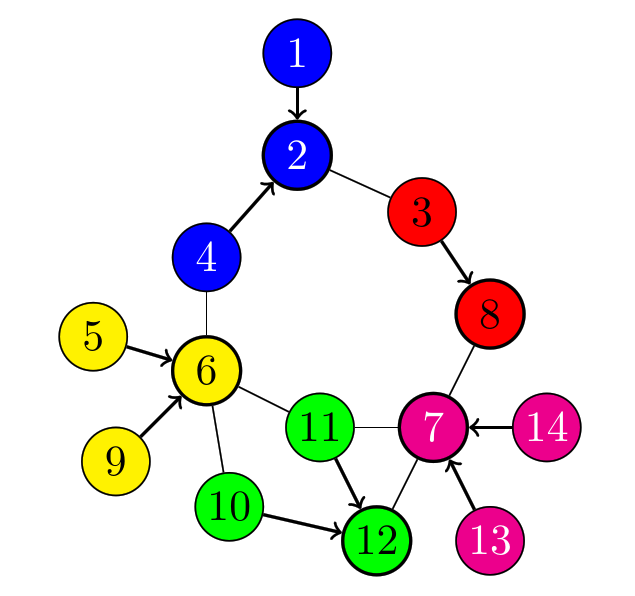
The following intuitive model was presented in [4] (actually, we corrected it a bit). We use variables \(x_i\in\{0,1\}\), \(i\in V\), to represent whether \(i\in S\), i.e., it is in the dominating set or not. The mapping \(f\) is represented by variables \(y_{ij}\in\{0,1\}\), \(\{i,j\}\in E\), that we interpret as \(y_{ij}=1 \iff f(j)=i\), that is, when \(i\) dominates \(i\). Define \(N(i):=\{j\in V : \{i,j\}\in E\}\) as the open neighborhood of \(i\in V\).
\begin{align} & \text{min} & & \sum_{i\in V}x_i \\ & \text{s.t.} & & \sum_{j\in N(i)} y_{ji} + x_i \geq 1 && i\in V \tag{BP} \\ & & & \sum_{j\in N(i)} y_{ij} \leq u_i x_i && i\in V \\ & & & x_i\in\{0,1\} && i\in V \\ & & & y_{ij}\in\{0,1\} && \{i,j\}\in E \end{align}
The objective function minimizes \(|S|\). Every vertex has to be dominated by a neighbor or is itself in \(S\); and no vertex can dominate more vertices than given by its capacity (the capacity is available only if the vertex is in \(S\)). Thus, the capacity constraints also link the \(x\) and \(y\) variables.
A ZIMPL model file (download) for the above instance is as follows:
Of course, you can use any modeling language you like, or generate your model (typically in .lp or .mps format) using a script. A bonus from using ZIMPL is that GCG can directly read the model file (when you compiled it with ZIMPL=true). So, we start GCG and
If GCG complains about a missing reader (because you compiled it with ZIMPL=false), alternatively run ZIMPL on the .zpl file to generate an .lp or .mps, and read this into GCG. Then start the optimization.
When we look at the optimal solution we find \(S=\{2,6,7,8,12\}\) as in the figure above.
This instance is too easy, so not much happens in GCG (in particular no branching). But when we try a larger instance (like this one with 250 vertices, 3780 edges, and uniform capacities of 5 for each vertex; taken from [5]), we witness a full-fledged branch-and-price algorithm at work to solve the capacitated dominating set problem:
GCG applied a Dantzig-Wolfe reformulation of the (''original'') input model to obtain an equivalent (''master'') integer program. The latter is solved by branch-and-price, that is, the linear relaxation in each node of the branch-and-bound tree is solved by column generation. GCG automatically detects what subproblems to form from the original problem.
We could stop here because our problem is solved. However, when you already know some theory about branch-and-price and Dantzig-Wolfe reformulation, we can provide you with some background and ways to influence the solution process.
In the compact model, the \(y\)-variables represent subsets \(T_i := \{j \in V : y_{ij}=1\} \subseteq N(i)\) of neighbors, for each vertex \(i\in V\). The important observation is that an (optimal) solution \(S\) to the capacitated dominated set problem corresponds to a partition of the vertices into (a minimum number of) subsets \(T_i \cup \{i\}\), one for each vertex \(i\in S\). The color classes in the figure above exactly reflect these vertex subsets.
We base an alternative model on this observation: Introduce a binary variable \(\lambda^i_T\in\{0,1\}\) for each possible subset \(T\subseteq N(i) \cup \{i\}\) of neighbors of \(i\in V\) (and \(i\) itself), where we require \(i\in T\) and \(|T|\leq u_i+1\). Denote by \({\cal T}_i\) the collection of all such vertex subsets for \(i\in V\). We then state a set partitioning model:
\begin{align} & \text{min} & & \sum_{i\in V}\sum_{T \in {\cal T}_i} \lambda^i_T \\ & \text{s.t.} & & \sum_{j\in N(i)}\sum_{T \in {\cal T}_j : i \in T} \lambda^j_T = 1 && i\in V & [\alpha_i] \tag{MP}\\ & & & \sum_{T \in {\cal T}_i} \lambda^i_T \leq 1 && i\in V & [\beta_i]\\ & & & \lambda^i_T\in\{0,1\} && i\in V,\, T\in {\cal T}_i \\ \end{align}
The objective is to miminimize the cardinality of the partition. Each vertex must appear in exactly one selected vertex subset and no more than one subset can be selected per vertex (could be none). In brackets, we indicate the dual variables per constraint. The cardinality of \({\cal T}_i\) is \(|N(i)| \choose u_i\), which in general can be exponential in \(|V|\). This suggests to solve the linear relaxation by column generation. The restricted master problem (RMP) contains only a (small) subset \({\cal T}'_i \subseteq {\cal T}_i\) for each \(i\in V\), initially, say, \({\cal T}'_i=\{\{i\}\}\). This initialization corresponds to the worst possible solution that every vertex is in the dominating set, but technically, this ensures feasibility of the RMP.
In order to determine a \(\lambda^i_T\) variable with \(T\in {\cal T}_i \setminus {\cal T}'_i\) of negative reduced cost (or to prove that none exists), we solve a pricing problem for each \(i\in V\). It reads as
\begin{align} z := \enspace & \text{min} & & 1 - \sum_{j\in N(i)} \alpha_j y_j - \alpha_i - \beta_i\\ & \text{s.t.} & & \sum_{j\in N(i)} y_j \leq u_i \tag{PP} \\ & & & y_j\in\{0,1\} && j\in V \end{align}
Note again that in this model, \(i\in V\) is fixed. As a solution, a capacitated subset \(T=\{j\in N(i) : y_j=1\} \cup \{i\}\) of neighbors of \(i\in V\) (and \(i\) itself) is selected. The objective function minimizes the reduced cost of the corresponding \(\lambda\)-variable (assuming again that \(i\in T\)).
When \(z<0\), variable \(\lambda^i_T\) is added to the RMP; the RMP is re-optimized, new dual variable values are obtained, and the process iterates. Otherwise, i.e., \(z\geq0\), we have proven optimality of the the linear relaxation of the master problem, and we can branch. As the master problem is a set partitioning problem, Ryan-Foster branching [6] is a good choice.
Actually, this alternative model results from a Dantzig-Wolfe reformulation of the compact model.
GCG by default does not make use of the row and column names, but it can be told to do so:


If you are interested, Potluri and Singh [5] made all their instances publicly available for download, together with the C code for their heuristics. We provide ZIMPL model files that read their input, for uniform and [variable](todo) capacities.
The authors .. provide the data they used in their publication [here] and a general ZIMPL that can read their instances as input is [here (local ressource)].
old
We would like to answer two questions:
was it worth it?
compare SCIP on the original model, GCG with our selected decomposition, and GCG automatic detection. performance profiles.
One conclusion of this use case is that you can do state-of-the-art computational research and propose a new (branch-and-price) approach to a combinatorial optimization problem, without the necessity to develop your own branch-and-price algorithm.
 1.8.17
1.8.17